Throughout your days in school, and maybe also in college and at the university, you have had a lot of different teachers and lecturers. Most likely you also have a favorite among these, a really good teacher who managed to completely capture your attention and focus. I had a math teacher once to whom the entire class payed close attention, in every lesson, but how did he do it? I guess he just had the talent for it, but what is the secret behind a really good lecture or an excellent presentation?
A place to start is to learn from experience lecturers, and if you want to create and give great presentations, there is a lot of pedagogical advice out there, from textbooks in teacher’s education to dedicated presentation services on the internet. Here is a little list of some of the advice that I found from some websites like www.ethos3.com and blog.ted.com which I have organized into four main points.
- Make structured presentations, minimize text on slides
- Use storytelling, relevant visuals and other multi-media sources, move your hands
- Speak in short burst and vary your vocal level, include elements of surprise
- Dress properly, smile and make eye contact
As a quite experienced lecturer in statistics at the Norwegian University of Life Sciences I am familiar with these advice, and although I still have a lot to learn, I have experienced that they do help to keep the attention from the students. But, why do they work? In this post I will address aspects of statistics, information theory, consciousness, attention and neuroscience which may help answer this question.
Measuring information
First of all, it is a matter of signal and noise, of course. That is what statistics is all about, and learning. From a varying, and at first apparently chaotic input, learning takes place when we discover some new order, a higher level of categorization, which can explain parts of the observed variation. It is my challenge as an educator to help my students bring order into chaos.
As I teach I provide input signals to my students. The perceived information content of an input signal may be measured or represented in different ways. In statistics we often use some signal-to-noise ratio, like the Fisher test statistic in Analysis of Variance (ANOVA). At any given time we are in possession of beliefs and theories about the outer world. If our belief about the world that generates incoming signals is plausible, the world appears to be to some extent predictable. Our inner model is good, and the unexplained part of what we observe (the noise) is small, which results in a high signal-to-noise ratio. On the other hand, if the input appears to be surprising and unpredictable, we have still something to learn about the processes that produce the input. Our inner belief model is poor, and a large part of what we observe appears as noise. According Hohwy (2013) life (and learning) is a continuous process of prediction error minimization by model (belief) adjustments.
Another measure of information content is the concept of mutual information, which is the difference in entropy (degree of disorder) between two variables, like the input from the world that we receive through our senses on one hand, and our predictions of the world generated by our current beliefs on the other. If these variables are similar, then the level of mutual information is high. The mutual information is linked to prediction error by the fact that the mutual information increases as the prediction error decreases.
Chaos and order
The more we learn, the better our inner models of the world become, and the better we can predict. We are simply less surprised by what we observe! The mutual information between the content of my lecture and the students understanding of it increases as order is brought into chaos. As a lecturer I must help my students to adjust their inner prediction models in such a way that they steadily become less surprised by what I say. When most of what I say appears to them to be predictable, the students are ready for the exam!
The goal is order and stability (predictability), but as Van Eenwyk (1997) states:
“.., whenever stability is a goal of adaption, chaos’s contribution rivals that of order. From that perspective, order and chaos reflect one another. Just where the line between the two exists depends largely on our ability to recognize similarities in the chaos.”
Hence, a good learning process is shifting constantly between chaos and order, then new chaos followed by new order, and so on. If I as a lecturer do not manage to create new chaos, my presentation becomes boring, fully predictable and unnecessary. There is no new order to be set. A good presentation should therefore strive to be somewhat unpredictable, because it is the discrepancy between the students’ beliefs and what I actually say, the surprise, which carries the potential of new learning.
Conditions for effective learning
I just mentioned attention, which of course is a necessary condition for learning, and another necessary condition is consciousness. A main message in this blog post is the following:
- A good learning process should raise the level of consciousness and trigger focused attention.
Sounds simple enough, and the list of good advice I presented earlier may help accomplish this. Let me first elaborate a bit on consciousness and attention before we discuss again the presentation advice I found.
Consciousness
Even though psychologists have shown that we may pay attention even if consciousness is low, and the opposite, that we can be quite conscious, but don’t pay attention (Hohwy, 2013), it is the combination of high consciousness AND high attention which is required for optimal learning conditions.
Consciousness, what is it really? We all have a first hand experience with it, yet it is so hard to explain, but new theories have been suggested, among which I find the integrated information theory (IIT) of Tononi (2008) and co-workers as the most promising. Put short the theory is based on the level of integrated mutual information inherent in a neural network. The model explains how a central part of a network, for instance the frontal cortical region, may reach above some imagined critical level of integrated information, which is believed to give rise to consciousness as an emergent property of the network.
[An emergent property is according to the Stanford Encyclopedia of Philosophy a state that “‘arise’ out of more fundamental entities and yet are ‘novel’ or ‘irreducible’ with respect to them.” In our case we might say that consciousness is a state which cannot be predicted from observing the reduced properties of the neurons and the neural network.]
What is really interesting by the IIT of consciousness is that the level of consciousness in a central cortical network may depend on and even be strengthened by connected sub-networks, such as sub-cortical circuits or cortico-cerebellar pathways, which will remain in the unconscious as long as these sub-networks are sufficiently segregated (loosely connected). This can for instance explain why we are not conscious of processes controlled by, for instance, the brainstem (e.g. heartbeat, breathing, body temperature control) and the cerebellum (like automated body movements). Neither are we directly conscious (luckily) of the immense data processing and data filtering going on in the sensory cortical regions like the visual cortex. However, the filtered information from the unconscious regions are gathered, integrated and potentially bound together in the central and “conscious part” of the neural network.
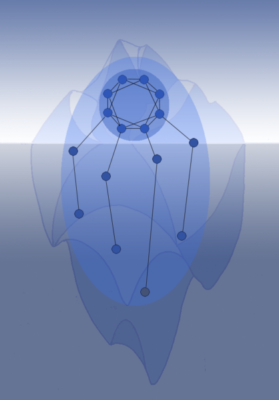 We may envision the conscious part of the network as the part of an iceberg which is visible above sea level, and the unconscious network regions as the large lump of ice below the surface supporting the conscious experience. The sea level is the critical level of mutual information required for consciousness to occur.
We may envision the conscious part of the network as the part of an iceberg which is visible above sea level, and the unconscious network regions as the large lump of ice below the surface supporting the conscious experience. The sea level is the critical level of mutual information required for consciousness to occur.
The iceberg above sea level represents the potential focal points that can be sampled by our conscious attention, as I also wrote about in the post “You random attention“. Further, and as explained by Hohwy (2013) we tend to choose an attention point which is surprising to us, that is, with a high prediction error.
Just think about it, imagine that you sit at a lecture listening to a not so engaging presentation about a well known subject. If something unexpected suddenly happens, like a cell phone ringing, your attention will immediately be drawn towards the surprising element.
So, here comes the element of surprise again. If a lecture is somewhat unpredictable, it will help to draw attention to it. But there is even more to this story. According to Friston (2009) attention is drawn strongest to a focal point with a combination of high prediction error (surprise) AND expected high information quality (precision).
Thus, our attention is drawn towards objects or actions that represent high level of surprise, which we in addition find to be reliably observed or to come from a trusted source. For example, we are more likely to pay attention when a highly respected person than a mere common takes the stand to give a speech.
Varying levels of consciousness
I guess you have seen, either with your own eyes or from pictures, icebergs of different shapes. Some are peaked, reaching relatively high above the surface, whereas others are just flat, barely visible above water. The first kind of iceberg may illustrate a high conscious state where the unconscious inputs are congruent and may be integrated into a strong, unified conscious state of mind.
Maybe you have some vivid memories from your youth or childhood? I also have some, and when I think back now, I can describe the given moment vividly, both what I saw, heard, and felt, and maybe also smell or taste was involved. Chances are also that such vivid memory experiences triggered some emotions, either good or bad. I think the reason I remember these moments so strongly is the fact that all unconscious inputs to the information integration network were congruent and could strengthen the conscious experience by adding different dimensions to it. My brain found the strongest focal point to attend to and the moment was glued to my memory!
The other type, the flat icebergs, represent the opposite. We are awake and conscious, but the input signals are either weak, noisy an unreliable or non-congruent and distracting. Think about the non-engaging lecture again… Attention points are hard to find or are very unstable on this flat surface. The conscious experience is weak and you are on the border of unconsciousness, maybe half a sleep or daydreaming. This state of mind is good for thought wandering, creativity and free association, but not optimal for learning “facts” from external stimuli.
Let us sum up what we have so far. In order to create a good learning experience through instruction a lecturer should:
- Increase attention: Keep an element of surprise, avoid being predictable and monotone, and be precise and trustworthy.
- Increase consciousness: Be congruent in the way that all inputs to the students add to a unitary, integrable experience.
Building a unitary, focused learning experience
This latter point is very important, but under-communicated. Sadly, I have seen so many presentations, especially at scientific conferences, were slides crowded with text are flashed before the eyes of the audience while the speaker tries, with good intentions, to express the same message in other(!) words, maybe with a non-engaging body language. What really happens is that the speaker conveys simultaneous, but non-congruent messages, one visual-lingual and another auditory-lingual. The brains of the audience then fail to integrate the information, the signal-to-noise ratio becomes low, and the body language of the speaker reduces the signal content even further. The top of the iceberg is flat and the audience enters a state close to unconsciousness. Some at the back row may even reach it entirely…
A small side comment fits well in here, because simultaneous non-congruent input is, in fact, also a type of communication, but a type which has been used for inducing hypnosis (!) by professional psychiatrists, like the famous Milton H. Erickson (Grinder and Bandler, 1981). A hypnotic state may be induced by simultaneous over-loading multiple senses for some time, until the hypnotist offers the patient to enter unconsciousness as an escape from the distracting and exhausting condition.
This is NOT what I would like my students to experience! Still, I fear that many lectures given at universities have similar hypnotic effects in the way students are over-loaded with non-congruent and non-integrable information!
Body language and voice
I mentioned non-engaging body language as a distraction in the above example, but “Moving your hands” was on the list of good advice, and moving your hands and a rich body language may increase the attention to the presentation if used properly.
I recently came across a post on the TED-blog by Alison Prato. The sub heading of the blog was “All TED Talks are good. Why do only some go viral?” There Vanessa Van Edwards, the founder of the consultancy called Science of People, gives some clues as to why some TED-talks become more popular than others. In their study hundreds of TED-talks were rated by 760 volunteers, and it is interesting to see how well the results fit the points I have made here.
Firstly, the most popular lecturers were by a test panel found to be more credible and having higher vocal variety. Edwards says:
“We found that the more vocal variety a speaker had, the higher their charisma and credibility ratings were. Something about vocal variety links to charisma and competence.”
Secondly, the lecturers that go viral had a richer body language than others. Edwards says, that this was a bit surprising: “We don’t know why, but we have a hypothesis: If you’re watching a talk and someone’s moving their hands, it gives your mind something else to do in addition to listening. So you’re doubly engaged. For the talks where someone is not moving their hands a lot, it’s almost like there’s less brain engagement, and the brain is like, “This is not exciting” — even if the content’s really good.”
I think they are onto something here, but according to my hypothesis, the body language must not only be rich, but it must also be congruent with the spoken word. Random hand-waving is distracting and lowers consciousness. Also, high vocal variety may be distracting and lower the impression of competence if used wrongly.
You can read the entire TED-blog by Alison Prato here.
The salience network for attention and prediction error minimization
Thus far my arguments for effective learning conditions have been quite theoretical and based on information theory, but there is also neuroscientific support for this. In later years neuroscience has shifted from a quite modular view of the brain, where functions (and malfunctions) are tightly connected to specific brain regions, to a view where brain functions are results of network processes and communication between regions. A series of functions and pathologies have lately been connected to networks and their properties (see e.g. Sporns 2011), among which attention has been connected to the so-called salience network (Menon (2015). This is a frontal lobe centered network, which includes brain regions like the dorsal anterior cingulate cortex (dACC), the anterior insula (AI), amygdala (A) and the ventral striatum (VS). Menon (2015) describes this network as
“…a high-order system for competitive, context specific, stimulus selection and for focusing ‘spotlight of attention’ and enhancing access to resources needed for goal-directed behavior”.
The network is connected to sensory cortices for external inputs, to the AI for self-awareness, to the emotion center of A and context evaluation in VS. The dACC is believed to be the center for evaluating surprise, or prediction error. This means that this network carries all necessary constituent needed to serve as a conscious attention network, and combined with the theory of Tononi, a high conscious state allowing strong attention, may be induced if all input information is congruent, and if the input fits emotion and interests and feels relevant, it is even better.
Advice explained
It is time to return to the list of good advice for presenters. Based on the theories of consciousness, attention and prediction error minimization as we have just worked through, we should be able to put some explanation to why these are good advice.
Here is the list again with explanation to why they improves learning:
- Make structured presentations, minimize text on slides
- Brings order into chaos, helps categorize
- Increases signal-to-noise ratio and mutual information
- Increases consciousness and attention
- Use storytelling, relevant visuals and other multi-media sources, move your hands
- If done properly, adds extra dimensions to the learning experience
- Congruent sensory input
- Unitary and integrable experience
- Increased consciousness and attention
- Speak in short burst and vary your vocal level, include elements of surprise
- Increasing prediction error among the listeners
- Increased consciousness and attention
- Dress properly, smile and make eye contact
- Increases trust
- Increases expected information quality (precision)
- Increased consciousness and attention
Personalized learning
However, it may not be as simple as this. If you ask people in the audience after a lecture whether they liked a presentation or not, you may receive quite different answers. This may be because we are all born with quite personal brain networks. The connections and their strengths in the network differ from one person to another, and we all integrate information in our own personal manner. Some may, for instance, place more emphasis on the emotional part via strong connections to the amygdala as they integrate the incoming information in the salience network, than others do.
I will not spend time on personality theory here, but the links to Walter Lowen (1982) and his entropy based model for personalities and even consciousness is apparent, and I may draw that link in a later blog post. I will here only remark that effective learning probably depends on the actual topology of the attention network of each and every student.
Acknowledgement
I’m very grateful to my good friend and colleague Dr. Helge Brovold at the National Centre for Science Recruitment in Norway for our many good chats about these topics and for his willingness to share his knowledge and interesting books with me.
References
Friston, K. (2009). The free-energy principle: a rough guide to the brain?. Trends in cognitive sciences, 13(7), 293-301.
Grinder, J. and Bandler, R. (1981). Trance-formations: Neuro-linguistic programming and the structure of hypnosis. Real People Pr.
Hohwy, J. (2013). The predictive mind. OUP Oxford.
Lowen, W. (1982). Dichotomies of the Mind. Wiley & Sons, NYC
Menon, V. (2015). Salience Network’. Brain Mapping: An Encyclopedic Reference, Academic Press: Elsevier.
Sporns, O. (2010). Networks of the Brain. MIT press.
Tononi, G. (2004) An information integration theory of consciousness. BMC Neuroscience, 5:42.
Van Eenwyk, J.R (1997). Archetypes and Strange Attractors. Inner City Books, Toronto, Canada.


Permalink